











VALL-E简介
VALL-E是微软研究院最新推出的文本到语音合成(TTS)技术,以神奇的三秒钟克隆声音的速度,保留说话者情感和声音环境,成为语音合成领域的一项重要突破。
技术背后的创新
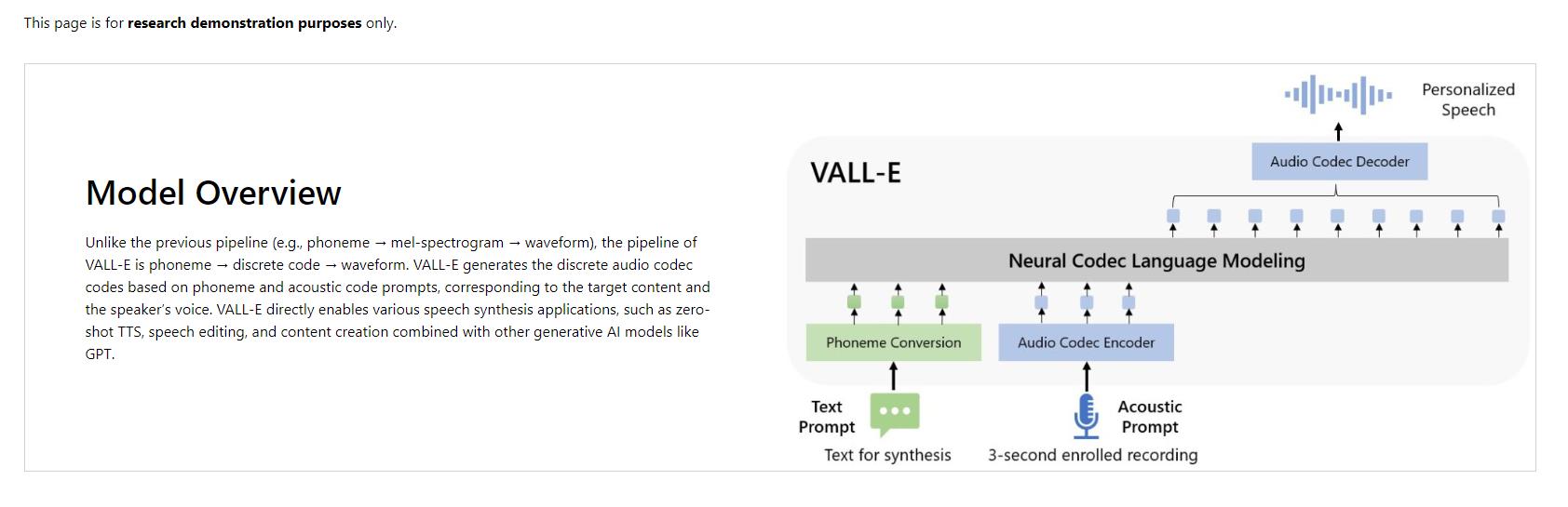
传统的TTS技术通常需要将文本转换成音频波形,涉及文本到梅尔频谱的转换,然后再到音频波形。这个过程对大量训练数据的依赖较大,对说话人和内容的控制不够灵活,也难以实现声音的个性化和多样化。VALL-E采用了一种全新的方法,将TTS看作一个条件语言模型的任务,通过生成离散的声码器代码,再由神经网络声码器解码成音频波形。
核心技术:EnCodec
VALL-E的声码器代码由EnCodec技术提供,该技术可以用极少的比特数来压缩和编码音频信号,保持高质量的同时实现了出色的灵活性。这种离散代码的生成使得VALL-E能够在合成中保留说话者的情感和声音环境,为用户提供更加个性化的语音体验。
VALL-E的应用场景
1. 零样本TTS
VALL-E支持零样本TTS,即不需要预先训练说话人模型,只需提供短暂的录音即可生成任何内容的语音。这项技术在语音合成领域带来了极大的便利。
2. 语音编辑
通过修改文本,VALL-E可以改变语音的内容,为那些需要修正或者增删语音信息的用户提供了便捷的工具。例如,它可以用于给短视频进行配音,或者修改演讲稿以更好地符合用户的意图。
3. 配音和英语朗读
对于公司、个人工作室等,VALL-E提供了高效、成本低廉的配音和英语朗读解决方案。通过克隆声音并输入文本,用户可以输出符合其需求的音色朗读,大幅度缩减成本,提高效率。
4. 内容创作
结合其他生成型AI模型如GPT,VALL-E可以用于创作有趣或有价值的语音内容。用户可以生成诗歌、故事,然后用自己喜欢的声音来朗读,吸引和影响听众。
总体而言,VALL-E的出现为语音合成领域带来了新的可能性,其灵活性和个性化特点使其在各种应用场景下都能发挥重要作用。通过三秒钟的音频样本,VALL-E让语音合成更加简便、灵活,为用户提供了全新的语音体验。





